
Your “Simple” System Design Is Probably Why It Fails in Production Systems
Four production failures that reveal what “simple” system designs ignore until it’s too late

Most system designs look clean on a whiteboard.
A few boxes. A few arrows. Maybe a database at the end.
And yet, those same systems are often the first to fail in production.
Not because they were complex, but because they were too simple to handle reality.
Before we go deeper, have you ever seen a system that looked perfectly designed…but failed the moment it hit production?
Hold that example in your mind. You’ll likely recognize it by the end.
In this article, I’ll show you four real scenarios where “simple” systems failed and what they were missing. You might have experienced all of them.

Welcome to “Beyond the Stack now.” This is Week 3 of the Mar month theme: Operational Excellence.
Over the last two weeks, we looked at how systems fail in production.
This week, let’s look at something more uncomfortable:
How many of those failures are designed in, long before production?
If you’re building or operating production systems, consider subscribing.
I write about how real systems behave—not just how they’re designed.
The Comfort of Simplicity
We tend to believe that simplicity reduces problems.
Fewer components. Fewer moving parts. Easier reasoning.
But production systems don’t reward simplicity in design.
They reward clarity under stress.
Not all failures happen under load. Some happen when your system is doing almost nothing.
And simplicity, when pushed too far, removes the things that make systems resilient—boundaries, isolation, and visibility.
Across these failures, one pattern repeats:
Simplicity increases coupling, removes boundaries, and hides failure modes.
If you follow system design content, you’ve likely seen explanations from publications like ByteByteGo
Most of them focus on how systems are designed.
This piece focuses on something else: why the simple designs fail in production.
Failure Scenario #1: The “Clean” Synchronous Chain
Let me start with something that looks perfectly reasonable.
A synchronous chain.
An API calls Service A, which calls Service B, which talks to a database.
No queues. No async flows. No extra components.
It’s clean. Easy to debug. Easy to explain. The design looked perfect.
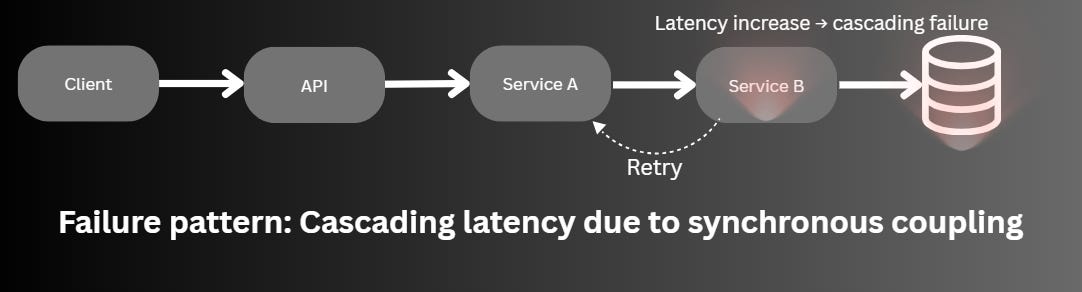
Until one day, the database slows down slightly.
Not a failure, just a bit slower than usual.
But that’s enough.
Service B starts taking longer.
Service A threads begin to block.
Requests pile up. Timeouts kick in.
Clients retry.
Now the system is not just slow, it’s overwhelmed by its own design.
Nothing actually “broke.”
But everything started failing.
This is not theoretical. During Amazon's 2018 Prime Day, a minor slowdown in an internal service triggered cascading failures across several components, including Sable (computation/storage), costing over $100 million in lost sales despite capacity planning. A recent AWS US-EAST-1 outage in October 2025 showed the same: a DNS "race condition" in DynamoDB rippled to EC2 and NLB health checks, dropping healthy capacity and spiking errors globally.
The issue wasn’t complexity.
It was a tight coupling disguised as simplicity.
Simplicity increased coupling. Coupling increased the blast radius.
Failure Scenario #2: The “Shared Database” Shortcut
A similar pattern shows up in data design.
Early on, sharing a database across services feels efficient.
No duplication. No synchronization issues. Just one source of truth.
It keeps things simple.
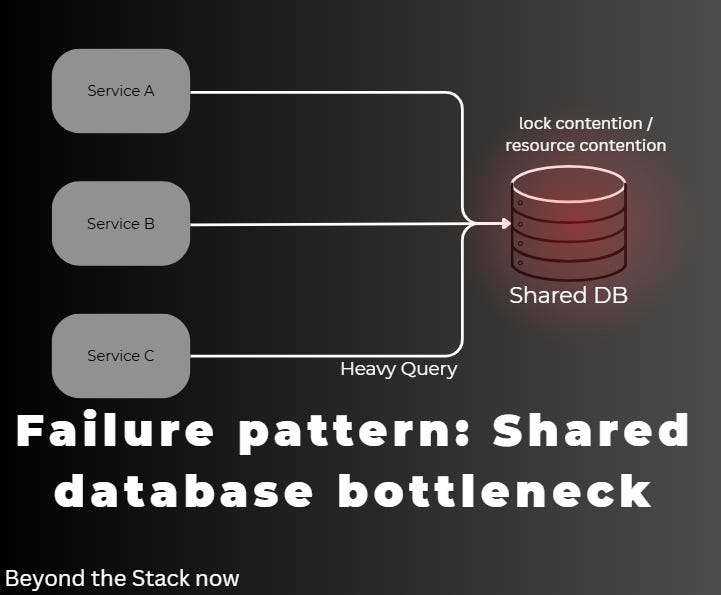
Until it doesn’t.
One service introduces a heavy query.
Another deploy introduces a schema change.
Lock contention increases.
Now every service is affected.
Debugging shifts from application logic to database internals.
Ownership becomes unclear. Coordination slows everything down.
This exact class of problem forced Uber to migrate from a monolithic PostgreSQL setup. As trips scaled to billions, the shared DB caused concurrency nightmares like double-dispatching drivers and demanded "tribal knowledge" for changes, risking full-system redeploys. They shifted traffic gradually via API gateways to microservices with dedicated data boundaries.
Again, nothing was “wrong” in isolation.
But the system had no boundaries to absorb change.
Simplicity removed boundaries. Boundaries are what keep systems operable.
Failure Scenario #3: The “Simple” Logging Strategy
Then comes the moment every team recognizes.
An incident.
Alerts are firing. The system is misbehaving.
You open logs.
There are logs everywhere.
But they don’t connect.
Each service tells its own story. None of them tells the whole story.

You start stitching timelines manually.
Guessing. Correlating. Re-running scenarios.
This is why Netflix built Edgar, their distributed tracing infrastructure. Traditional logs failed to reconstruct failures across microservices; tracing added session IDs, service topology, retries, and latencies, with hybrid sampling for 100% critical paths. A request spanning dozens of services became debuggable, slashing MTTR.
The system was simple to build.
But not simple to understand when it mattered.
Simplicity in code created complexity in debugging.
At this point, this pattern should feel familiar.
Quick question:
Which one have you experienced more in your systems?
– Cascading failures from synchronous calls
– Shared database bottlenecks
– Debugging nightmares due to poor observability
Drop your answer below. I’m curious what shows up most often in real systems.
Failure Scenario #4: The “Idle System” That Kept Failing
And sometimes, the most interesting failures are not under high load, but when the system is barely doing anything at all.
Now, let me bring this closer.
We had an application running in production on Amazon Web Services ECS, backed by Cockroach DB, with high availability handled through Amazon Route 53.
Everything looked solid.
UAT was clean. Stable. No signals of concern.
We went live. The next day, alerts started. Not once. Every day.
Health checks were failing. Incidents were triggered.
But the system looked fine.
No spikes. No crashes. No obvious errors.
It took time to see what was really happening.
The issue wasn’t the load. It was the absence of it.
Because production traffic was low:
Connections in the pool stayed idle.
Idle connections crossed timeout thresholds.
They were silently dropped.
The next request picked up a dead connection
And just like that, health checks started failing.

Nothing was broken. But nothing was reliably working either.
This is a well-known class of issue in connection pooling systems, especially in distributed databases and managed infrastructure, where idle timeouts are enforced at multiple layers (application, driver, network, database).
This is a well-known class of issue in connection pooling, especially with Cockroach DB on serverless or ECS, where idle timeouts stack across layers (app, driver, network, DB), so pools need aggressive settings.
The system had been designed for:
normal traffic
high traffic
But not for:
no traffic
And that was enough to trigger incidents.
The fix was straightforward.
Tune the connection pool.
Validate connections before reuse.
Adjust idle timeouts.
But every fix came with a trade-off.
More validation added latency.
More aggressive recycling affected performance.
This is where the deeper truth becomes visible:
When simplicity ignores real-world states, the cost shows up later as operational trade-offs.
The Pattern Behind These Failures
Across all these scenarios, the pattern is consistent.
“Simple” systems tend to:
Maximize coupling
Remove boundaries
Ignore failure modes
Assume stable conditions
They optimize for how systems look during design.
But production systems are judged by how they behave under stress, variability, and uncertainty.
Simplicity reduces design effort—but increases operational uncertainty.
Redefining “Good” System Design
Experienced engineers eventually stop asking:
“How do I make this simpler?”
And start asking:
“Where will this break, and how contained will it be?”
That shift changes everything.
You introduce queues, not for complexity, but for isolation.
You separate data, not for purity, but for ownership.
You invest in observability, not for visibility, but for survival.
The system becomes more complex on paper.
But more predictable in production.
Read Next
Series Note
This article is part of my March series on Operational Excellence, where I examine how modern systems fail in production and how engineers can design for reliability from the start.
It also sits at the intersection of two ongoing tracks on Beyond the Stack now:
System Design — how architectural decisions shape system behavior long before production.
Operational Excellence — how efficiency, cost, and predictability are designed (or ignored) long before dashboards start showing problems.
Explore the full System Design Series
https://beyondthestacknow.substack.com/t/system-design
Explore the full Reliability and Resilience Engineering Series
https://beyondthestacknow.substack.com/t/operational-excellence
Closing Thought
A system that looks simple on a whiteboard but fails under load is not simple.
It is incomplete.
The real goal is not to design systems that are easy to draw.
The goal is to design systems that remain understandable and controllable when things go wrong.
Most outages don’t come from complex systems.
They come from simple systems meeting complex reality.
If that line hits, it’s worth sharing.
Your Turn
Have you seen a “simple” design fail in production?
What was the hidden cost?
If this resonated with you, share it with someone who still believes “simple” always means “better.”
And I’d like to hear from you:
What’s a “simple” design decision that came back to hurt you in production?
Real stories > perfect architectures.