
The Log Statement That Waited Years to Break Production
If you build systems that run in production, not just pass code reviews, this story is for you. Consider this a reminder to re-evaluate the “small” things you’ve postponed fixing.


The code was correct.
The deployment was clean.
The system still took six hours to finish.
Because correctness is not the same as operational safety.
Welcome to Beyond the Stack Now, where each article explores engineering decisions and the why behind the tech stack, not just the tools themselves.
For March 2026, the focus is on Operational Efficiency and Scaling. Subscribe to this newsletter so that you don’t miss any edition.
Thank you for the consistent support and engagement during last month’s theme on Reliability. Based on that experience, I made a deliberate shift in how I structure this newsletter: instead of covering broad topics sporadically, I now focus on one core theme each month and explore it through three lenses - Code, AI, and System Design. I’d genuinely like to know if this format is working for you, or if there’s a different structure you’d find more valuable.
That change has meaningfully altered how I think about writing and teaching engineering concepts. It has also helped the community grow to 78 subscribers, a 13% increase over the last month.
Previous Read
Our Actual Production Environment
For years, our application ran without drama.
It was hosted on a VSI-based environment. We knew there was excessive logging. We also knew that one background process showed minor, intermittent delays. Both were visible. Both were discussed. And both were consistently marked as “not urgent.”
Nothing was failing. SLAs were green. There was always something more important to fix.
Then we moved the application to the cloud.
At first, nothing changed.
Same code. Same behavior. The excessive logging was still there. The intermittent delay still appeared occasionally. Still not urgent. If anything, the cloud migration reinforced our belief that these were cosmetic issues, not operational risks.
Production Broke
Until one day, that “minor delay” turned into a six-hour execution.
No deployment that day.
No infrastructure outage.
No sudden spike in traffic.
Just a process that used to complete reasonably fast, but now it’s stuck for hours.
This is usually the moment teams start blaming infrastructure, autoscaling, or the cloud provider. I didn’t, and that made all the difference.
When something like this breaks in your system, what’s your first instinct - code, data, or infrastructure? I’d be interested to hear how others approach it.
Root Cause
When I dug into the execution path, the root cause was almost embarrassing in its simplicity.
Inside a for loop, there was a log statement.
That log statement used string concatenation.
And the loop iterated over every record in a database table.
Until recently, that table was small enough for the inefficiency to hide. But the previous weekend, we had deployed a change that loaded roughly 272,000 records into it.
The business logic was still correct.
The algorithm hadn’t changed.
The system didn’t suddenly become “slow.”
We had simply crossed the threshold where a careless logging decision became an operational failure.
Before changing anything in production, I didn’t jump straight to a fix. In a situation like this, what would you validate first before touching the code?
I wrote a small, isolated program, essentially a focused unit test, to validate the hypothesis: was the delay truly caused by the logging inside the loop, or was something else contributing to it?
That experiment made the answer unambiguous. With the log statement in place, execution time scaled linearly with record count. Removing it collapsed the delay immediately.
At that point, this was no longer a suspicion. It was proven.
String concatenation in loops is notoriously expensive, even for disabled debug logs, as it builds strings upfront—up to two orders of magnitude slower than parameterized logging. (Ref: DZone Article)
A quick pause here: if your code logs inside loops, retries, or batch jobs, you might want to revisit those assumptions before data growth forces the conversation.
A single log statement, inside a loop, multiplied by hundreds of thousands of iterations, quietly consumed CPU, memory, and I/O—until the system collapsed under its own observability.
Other Well-Known Outages (Due to Logging)
Excessive logging has caused numerous production failures beyond my story. For instance, A Fortune 500 IoT platform's hotfix added logging that blocked customers from managing smart lock codes for eight hours, requiring a rollback.
In another case, a Node.js API lost 40% throughput using synchronous console.log calls, blocking the event loop during high load. (Ref: Dev. to article)
Solution
Once I fixed that loop and removed the problematic logging, the six-hour delay disappeared.
So did the excessive logging issue we had been ignoring for years.
Two “non-urgent” problems.
One line of code.
This incident permanently changed how I think about operational excellence.
Operational failures don’t always come from bad architecture or insufficient infrastructure. Very often, they come from small, local code decisions whose cost only becomes visible when data grows, environments change, or execution patterns shift.
What worked on VSI stopped working in the cloud—not because the cloud is worse, but because the cost model is different. CPU, logging, serialization, and I/O behave very differently when scale comes into play.
If this sounds familiar, share this edition with your team, especially with engineers working on batch jobs, logging, or migrations.
The real mistake wasn’t the log statement.
The mistake was assuming that “working fine” meant “operationally safe.”
Operational excellence is not about reacting faster when systems break. It’s about treating visible inefficiencies as future incidents, especially when they sit inside loops, retries, background jobs, and observability code.
Operational excellence demands treating logging as production code, per SRE principles: eliminate toil, ensure observability without overload, and scale design.
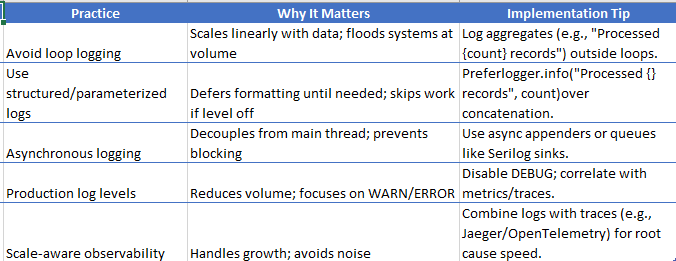
Code-Level Takeaways
Never log inside unbounded or data-driven loops.
If you must, log aggregates or summaries—not per-record details.Treat string concatenation in hot paths as a performance smell.
Especially in managed runtimes, this directly impacts allocation rate and GC pressure.“Not urgent” issues in batch jobs are deferred incidents.
Data growth will eventually make them urgent.Observability code is production code.
Logging, metrics, and tracing must be reviewed with the same rigor as business logic.Always ask: what happens when this runs on 10x data?
If the answer is unclear, the code is already risky.
If this resonated, consider subscribing to Beyond the Stack. Each edition focuses on the decisions below the surface, where real operational excellence is won or lost.
Like if this made you rethink a “non-urgent” issue you’ve been ignoring.
Restack to help others see how small code decisions quietly turn into production incidents.
Share this with your team before logging, retries, or batch jobs become your next six-hour delay.
Comment: When something slows down in production, where do you look first—code, data, or infrastructure?
Until then, ask yourself one question and don’t answer it casually:
If this line of code runs 10× more often tomorrow,
Is the system still safe to operate?
If the answer is “I’m not sure,”
The risk is already in production.
Incidents like this mark quiet breakpoints in an engineer’s career.
Not promotions. Not new titles.
But moments where you stop asking “does this work?” and start asking “will this survive?”
I explore more of these moments, technical, operational, and personal, in my e-book, Breakpoints of a Career.
Read Next
Series Note
This article is part of my March series on Operational Efficiency and Scaling.
If you care about how systems behave over time, not just whether they’re technically “up”, the next pieces in this series will matter to you.
This edition sits at the intersection of two ongoing tracks on Beyond the Stack Now:
Programming & Code-Level Decisions — how small, local choices in loops, logging, memory usage, and control flow quietly shape system behavior in production.
Operational Excellence — how efficiency, cost, and predictability are designed (or ignored) long before dashboards start showing problems.
Explore the full Programming & Code-Level Decisions Series
https://beyondthestacknow.substack.com/t/programming-languages
Explore the full Operational Excellence Series
https://beyondthestacknow.substack.com/t/operational-excellence
Across this March series, the goal is not to optimize prematurely or chase micro-benchmarks. It is to surface a harder truth:
Systems often fail operationally long before they fail functionally.
In February, the focus was on Reliability as a Design Choice - how systems either survive failure or amplify it based on decisions made early.
In March, the focus shifts slightly but deliberately.
Because systems don’t fail only when they’re unreliable.
They also fail when they become slow, expensive, noisy, and difficult to operate, even while still returning correct results.
Explore the full Reliability and Resilience Engineering Series
https://beyondthestacknow.substack.com/t/reliability
If you care about how systems behave at scale, under data growth, and under real operational pressure, the rest of this series builds directly on what we explored here.
Subscribe to follow the remaining March editions as the series continues.